
Climate refugees: why we can't yet predict where millions of displaced people will go
Derek Groen, Brunel University London and Diana Suleimenova, Brunel University London
In the near future, global warming is expected to create millions of climate refugees, and individuals and organisations are already searching for ways to help them. Some ideas are obvious, such as improving conditions in refugee camps.
But there are also more high-tech projects such as using algorithms to forecast where displaced people will travel to. Such forecasts are crucial. They can help support organisations prepare in the right places, they can evaluate current policy (by assessing a counterfactual “what if” scenario) and they can also help predict refugee populations in remote or dangerous areas where there is little empirical data.
So we can predict where climate refugees will go, right?
No. Despite bold and excitable claims that refugee forecasting is largely resolved, we are not convinced. As computer scientists who work on this exact problem, such claims seem like a painful example of running before we can walk.
Almost four years ago, we started to research how people fled from armed conflicts. Many people were displaced due to the Arab Spring and the Syrian War, but little work had been done to predict where they could end up.
With our colleague David Bell, we created a tool that could help, and published our work in Nature Scientific Reports. Our tool represents every person as an independent agent, and then uses simple rules-of-thumb derived from scientific insights – for instance “people tend to avoid travelling through mountains when it is raining” – to determine when they will move next, and to where.
This is different from “machine learning” approaches, which use historical data to “train” the algorithm to generate rules and thus predictions. So, for example, machine learning might be given this sort of data: “the number of people that arrived in a refugee camp close to a mountainous area in a conflict that occurred perhaps many years ago, or more recently but in a different country.” The main issue is that historical data used for machine learning is always quantitative, and never is about the conflict that the simulation is directly developed for.
To see how our method worked in practice, we tested our tool against UNHCR data from three recent conflicts in Burundi, the Central African Republic and Mali. Our tool correctly predicted where more than 75% of the refugees would go.
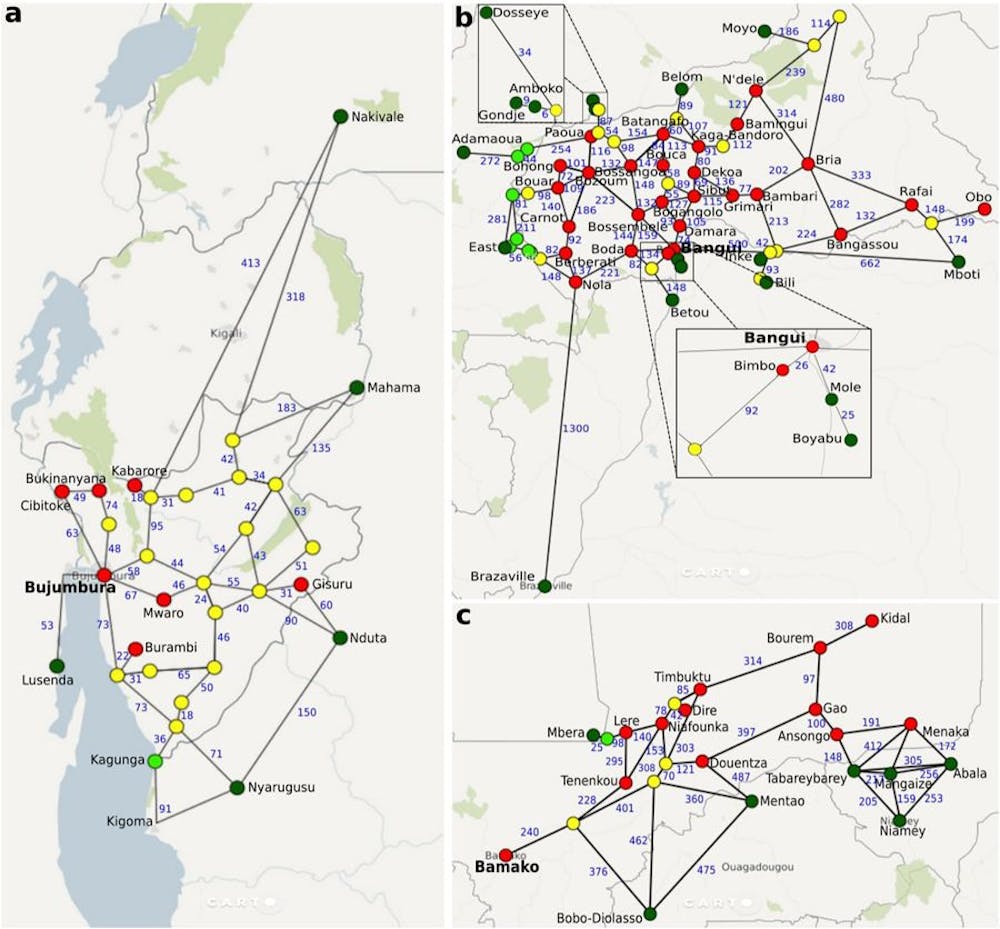
We have since applied our analysis to refugees fleeing conflict in South Sudan, as part of the HiDALGO project. In this study, forthcoming in the Journal of Artificial Societies and Social Simulation, we also looked at how policy decisions like border closures affected the movement of refugees into neighbouring countries, such as Ethiopia or Uganda.
We found there was indeed a link – closing the Uganda border in our model causes 40% fewer “agents” to arrive in camps after 300 days, and that effect lingers even after we reopened the border on day 301. Our tool correctly predicted where 75% of the refugees would actually go in real life.
But doing a correct “retrodiction” in these historical cases does not mean that you can do a forecast. Forecasting where people will go is much harder than predicting a historical situation, for three reasons.
- Every model makes assumptions. For instance, a model that forecasts where refugees go might makes assumptions about their mode of transport, or the likelihood that they stay overnight in a place where violence has previously occurred. When forecasting, we need to know what happens when we give these assumptions a little shake (we examine this in the VECMA project). The less evidence we have for an assumption, the more we need to shake it and analyse how our model responds. Machine learning models generate implicit (and ill-justified) assumptions automatically when they are trained – for example, chosen destinations correlate with the stock value of company X. In agent-based models, these assumptions come from physical factors like the presence of mountains or armed groups, and are explicitly testable.
- Forecasting one thing requires you to forecast many other things as well. When we forecast how people escape conflict, we must forecast how the conflict will evolve. And that could depend on future market prices, weather/climate effects, or political changes, all of which would need forecasting too. To be clear: we did not require any of these models when we validated our predictions against a historical situation, so we are building new models just to make forecasts possible.
- Forcibly displaced people are usually fleeing from unexpected and disruptive events. Here the data upon which the machine learning algorithms are “trained” is incomplete, biased or often non-existent. We argue that agent-based models are more effective because they do not need training data, and benefit from understanding the processes that drive forced displacement.
So we have not cracked it.
Yes, forecasting is hard. We do not yet know where climate refugees and other forcibly displaced people are going. We still need huge supercomputers just to forecast next week’s weather.
So it pays to be suspicious of the idea that refugee forecasting is already solved, especially if linked to claims that the “next frontier” for computer scientists is in (controversially) extracting data from vulnerable refugees who are often unaware of the privacy and security risks. Given how hard it remains to predict where the millions of climate refugees will go, the “next frontier” is still the last frontier.
Derek Groen, Lecturer in Simulation and Modelling, Brunel University London and Diana Suleimenova, PhD Researcher, Computer Science, Brunel University London
This article is republished from The Conversation under a Creative Commons license. Read the original article.

